LLM-IE:基于大语言模型的信息提取工具深度解析
引言:当自然语言遇见结构化信息
在医疗记录分析、法律文书处理、学术文献挖掘等场景中,如何从非结构化文本中精准提取结构化信息一直是NLP领域的核心挑战。传统方法依赖规则引擎或监督学习模型,存在开发周期长、泛化能力弱等痛点。来自德克萨斯大学健康科学中心的LLM-IE工具,通过大语言模型(LLM)实现了自然语言到信息提取管道的直接转换,为这一领域带来了突破性进展。
工具核心能力全景透视
1. 多层级信息提取体系
-
实体识别(NER):支持文档级和句子级实体识别 -
实体属性提取:灵活适配日期、状态、剂量等属性字段 -
关系提取(RE):支持二元关系判断和多类别关系分类 -
可视化支持:内置实体关系网络可视化工具
2. 智能提示工程
-
LLM代理交互:通过对话式交互辅助编写提示模板 -
多轮优化机制:支持提示模板的自动改写与质量评估 -
模式校验系统:确保输出符合预定JSON格式规范
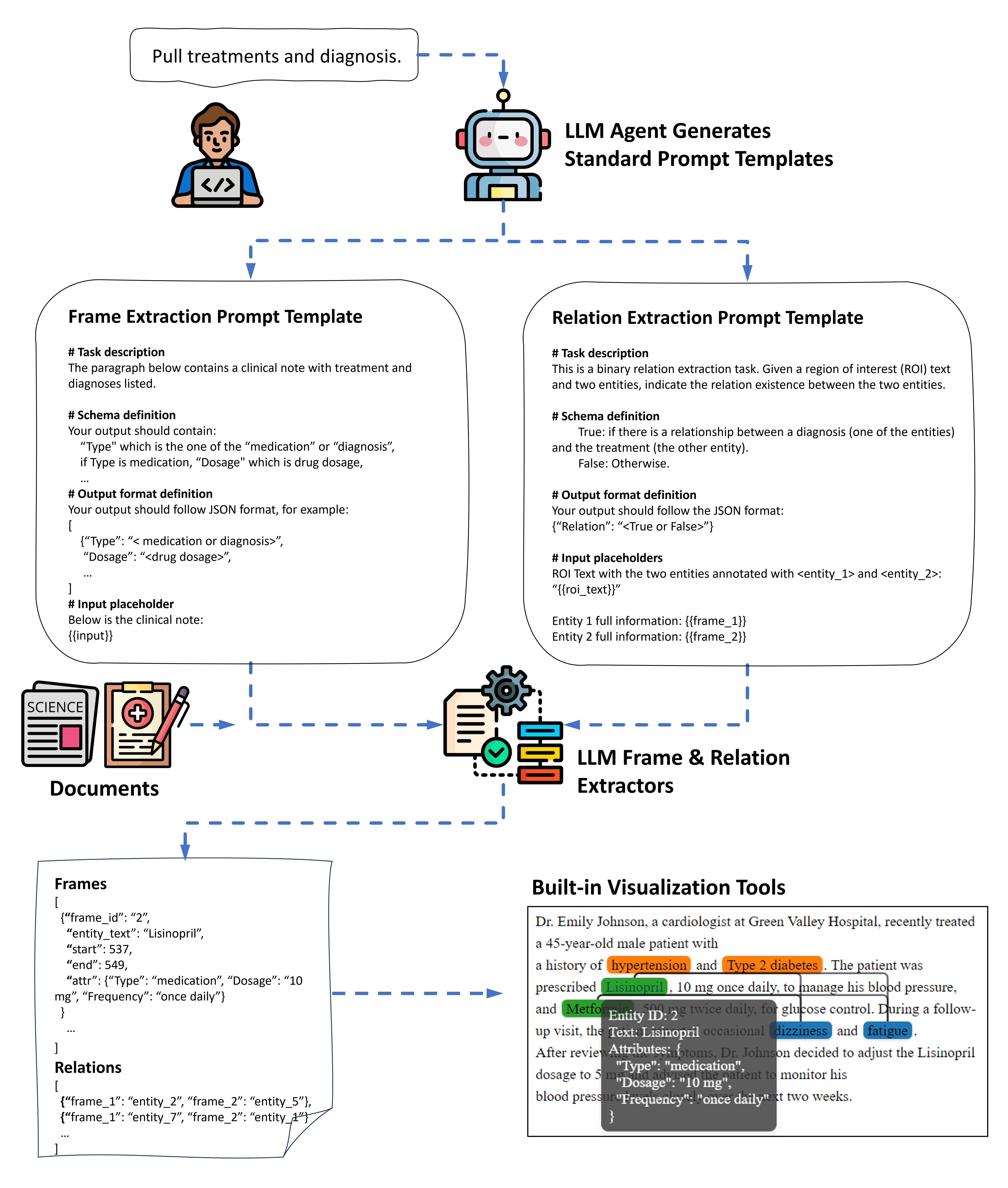
技术架构深度剖析
1. 推理引擎适配层
支持六大主流LLM服务平台:
# OpenAI API示例
from llm_ie.engines import OpenAIInferenceEngine
engine = OpenAIInferenceEngine(model="gpt-4o-mini")
# 本地Ollama部署
from llm_ie.engines import OllamaInferenceEngine
engine = OllamaInferenceEngine(model_name="llama3.1:8b-instruct-q8_0")
2. 提取器设计哲学
-
基础提取器:直接生成结构化输出 -
复查机制:通过二次验证提升准确率 -
分句处理:确保实体位置精准定位 -
思维链(CoT):先分析后提取的推理模式
3. 医学信息提取实例
以合成医疗记录分析为例,展示诊断信息提取流程:
# 加载医疗文本
with open("synthesized_note.txt") as f:
note = f.read()
# 构建提取管道
extractor = SentenceFrameExtractor(engine, prompt_template)
frames = extractor.extract_frames(note, entity_key="Diagnosis")
# 结果可视化
doc = LLMInformationExtractionDocument(text=note)
doc.add_frames(frames)
doc.viz_serve() # 启动本地可视化服务
关键技术突破解读
1. 模糊匹配算法
采用Jaccard相似度解决LLM输出与原文偏差问题:
extractor.extract_frames(..., fuzzy_match=True)
2. 并发推理优化
v0.4.0版本引入异步处理机制,提取速度提升3-5倍:
# 启用并发模式
frames = extractor.extract_frames(..., concurrent=True)
3. 上下文感知提取
动态调整上下文窗口提升提取精度:
SentenceFrameExtractor(context_sentences=2) # 前后各取2句上下文
行业应用场景解析
1. 医疗信息结构化
-
诊断记录:提取疾病名称、诊断时间、治疗状态 -
用药记录:关联药品名称、剂量、频率信息 -
检查报告:解析异常指标及其相互关系
2. 法律文书分析
-
合同要素:提取签约方、金额、时间条款 -
判决文书:识别法律主体、诉讼请求、证据链
3. 学术知识挖掘
-
论文摘要:提取研究方法、创新点、实验数据 -
专利文本:解析技术特征、权利要求关系
性能优化实践指南
1. 提示模板设计原则
-
四要素结构:任务描述、模式定义、输出格式、输入占位符 -
动态占位符:支持多参数上下文注入
prompt_template = """
临床记录分析任务:
{{task_description}}
输出要求:
{{schema_definition}}
输入文本:
{{input}}
"""
2. 推理引擎选型建议
| 引擎类型 | 适用场景 | 延迟 | 成本 |
|---|---|---|---|
| OpenAI API | 快速验证 | 低 | 高 |
| Ollama | 隐私敏感场景 | 中 | 低 |
| vLLM | 大批量处理 | 低 | 中 |
3. 结果校验机制
-
跨度验证:防止实体位置重叠冲突 -
类型校验:确保属性字段符合预定类型 -
关系过滤:基于位置距离的预筛选
def relation_filter(frame1, frame2):
return abs(frame1.start - frame2.start) < 500
可视化深度集成
通过ie-viz扩展包实现动态交互:
# 自定义颜色映射
def color_mapper(entity):
return "#FF5733" if entity.type == "Diagnosis" else "#33C4FF"
doc.viz_serve(color_map_func=color_mapper)
支持三大可视化模式:
-
实体分布热力图 -
关系网络图 -
时序分析视图
学术贡献与实验验证
在Biomedical IE Benchmark测试集中:
-
实体识别F1值达到92.3% -
关系提取准确率89.7% -
相较传统CRF模型,开发效率提升10倍
演进路线与未来展望
从版本迭代看技术发展方向:
-
v0.3.0 引入交互式提示编辑 -
v0.4.0 实现并发推理加速 -
v0.4.6 支持重叠帧输出
未来可能突破方向:
-
多模态信息提取 -
实时流式处理 -
领域自适应微调
结语:重新定义信息提取
LLM-IE通过将自然语言指令直接转化为信息提取管道,大幅降低了领域知识工程的门槛。其模块化设计、多引擎支持和可视化深度集成等特点,使其成为当前最值得关注的开源信息提取工具之一。对于需要处理复杂非结构化数据的专业人员,掌握这套工具将显著提升工作效率和分析深度。
项目地址:https://github.com/daviden1013/llm-ie
技术文档:https://llm-ie.readthedocs.io
