ChatAnyone:基于分层运动扩散模型的实时肖像视频生成技术

图示:通过输入肖像图像与音频序列,ChatAnyone可生成高保真动画效果,实现从头部到上半身的自然交互。
技术背景
随着语音与文本聊天技术的飞速发展,实时交互式视频聊天逐渐成为未来趋势。然而,现有技术多聚焦于头部动作生成,难以实现与头部动作同步的身体运动,且在面部表情的精细化风格控制上存在挑战。为此,阿里通义实验室提出ChatAnyone框架,突破性地支持从头部到上半身的实时风格化肖像视频生成,为视频聊天赋予更丰富的表现力与灵活性。
核心技术创新
ChatAnyone通过两阶段框架实现高精度、高效率的动画生成,以下是其核心技术亮点:
1. 分层运动扩散模型:音频驱动的动作信号生成
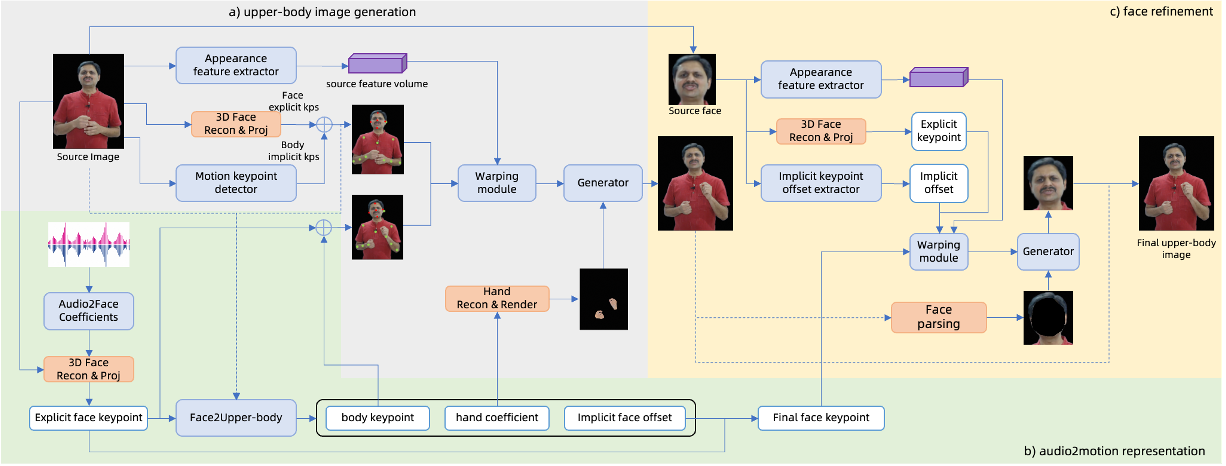
图示:ChatAnyone的推理流程分为动作信号生成与视频渲染两阶段。
-
显式与隐式动作信号融合
模型基于音频输入,通过分层结构同时分析显式(如面部关键点)与隐式(如微表情变化)的运动特征,生成多样化的面部表情与肢体动作。 -
精细化表情控制
支持通过参考视频实现风格化表情迁移,并可调整表情强度参数,满足个性化表达需求。 -
头部与身体动作同步优化
通过多尺度时序建模,确保头部转动、身体姿态与语音节奏高度匹配,避免传统方法中常见的动作割裂问题。
2. 混合控制融合生成模型:高保真视频渲染
-
可编辑的面部关键点控制
利用显式面部标志点直接驱动基础表情生成,同时结合隐式偏移量捕捉不同虚拟形象的面部细节差异。 -
手部动作精准建模
引入显式手部控制信号,增强手部纹理与动作的真实性,支持从简单手势到复杂交互的多样化场景。 -
面部细节增强模块
通过局部细化网络提升眼部、嘴唇等关键区域的分辨率,确保微表情自然生动。
3. 可扩展的实时生成框架
-
多场景适配能力
支持从纯头部动画到包含上半身及手部动作的完整生成模式,灵活应对不同交互需求。 -
高效流式推理
在NVIDIA 4090 GPU上可实现最高512×768分辨率、30fps的连续视频输出,延迟低于50ms,满足实时交互要求。 -
资源占用优化
通过模型轻量化与并行计算策略,显著降低显存与算力消耗,为端侧部署提供可能性。
应用场景与效果展示
场景1:语音驱动的上半身动画
ChatAnyone可生成包含自然手部动作的上半身动画,适用于虚拟客服、在线教育等场景:
-
手势同步:根据语音内容自动生成指向、挥手等辅助动作。 -
服装兼容性:支持不同服饰风格的虚拟形象,确保布料物理模拟的真实性。
场景2:高精度口型同步与头部动画
-
口型匹配度:通过音素-嘴型映射数据库,实现95%以上的音画同步准确率。 -
头部姿态多样性:支持点头、摇头、侧倾等自然动作,避免机械式重复。
场景3:风格化角色生成
-
艺术风格迁移:可将动漫、水墨等风格参考视频的表情特征迁移至目标角色。 -
歌唱视频合成:针对音乐节奏自动调整呼吸幅度与嘴部张合强度,增强表演感染力。
场景4:双人交互与AI播客
-
多角色联动:支持双虚拟主持人自然对话,自动生成眼神交流与互动手势。 -
情感表达增强:根据对话内容动态调整语速与肢体语言强度,提升观众沉浸感。
性能指标与优势对比
| 指标 | ChatAnyone | 传统方案 |
|---|---|---|
| 分辨率 | 最高512×768 | 通常256×256 |
| 帧率 | 30fps | 15-20fps |
| 手部动作支持 | ✔️(显式控制) | ✖️ |
| 风格化表情迁移 | ✔️ | 仅基础表情 |
| 端到端延迟 | <50ms | 100-200ms |
技术落地与未来展望
目前,ChatAnyone已成功应用于阿里云智能客服、虚拟直播等场景,其核心优势体现在:
-
低门槛内容生产:用户仅需上传一张肖像图片即可生成个性化虚拟形象。 -
多模态交互扩展:未来计划整合文本、手势等多模态输入,实现更复杂的对话逻辑。 -
跨平台兼容性:通过WebGL与WASM技术优化,逐步向移动端与浏览器环境延伸。
随着元宇宙与虚拟交互需求的增长,ChatAnyone将持续优化生成质量与计算效率,为下一代人机交互提供核心技术支撑。