DreamActor-M1:基于混合引导的全身人像动画技术,实现高表达力与鲁棒性
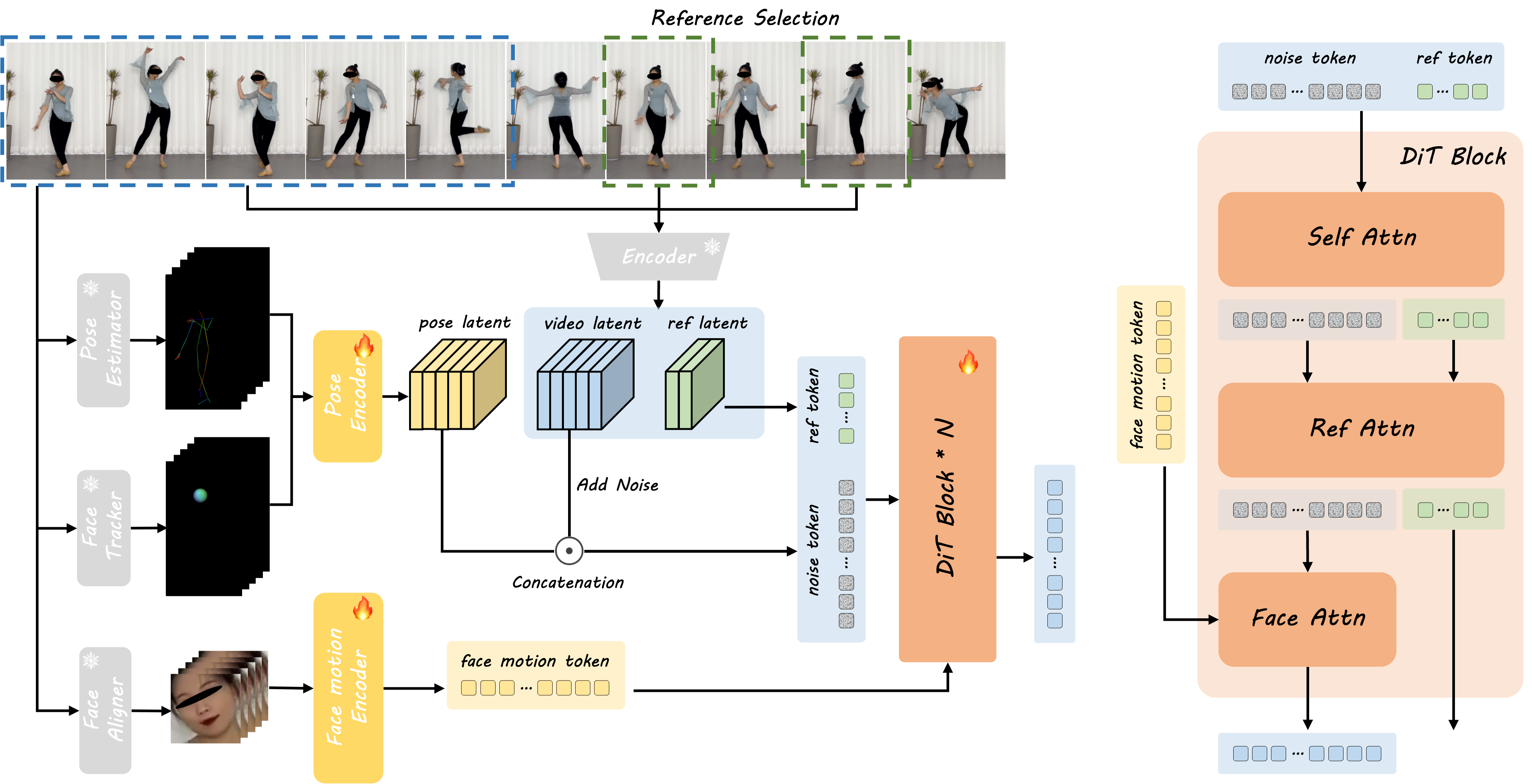
Bytedance Intelligent Creation 团队近期提出了一种革命性的人像动画框架——DreamActor-M1。该技术基于扩散变换器(DiT)架构,通过混合引导策略实现了细粒度全局控制、多尺度适应性和长期时间一致性,能够从单张参考图像生成高度逼真且身份一致的人像动画视频。无论是肖像、上半身还是全身动画,DreamActor-M1 均展现出卓越的视觉效果与运动连贯性。
为什么需要新一代人像动画技术?
传统基于图像的人像动画方法虽然在身体与面部动作合成方面取得进展,但仍存在三大核心挑战:
-
控制粒度不足:难以精准协调面部微表情与全身动作 -
尺度适应性差:无法同时处理肖像特写与全身视图的生成 -
时间连贯性弱:复杂动作下易出现画面闪烁或身份偏移
DreamActor-M1 通过混合运动引导、渐进式多尺度训练和互补视觉参考机制,系统性地解决了上述问题,为人像动画领域树立了新的技术标杆。
核心技术解析:三大创新突破
1. 混合运动引导:精准控制面部与身体动作
-
面部动作编码:通过面部运动编码器提取隐式表情特征,捕捉微表情细节 -
3D头部球面建模:精确还原头部旋转角度与视线方向 -
骨骼驱动系统:基于3D人体骨骼数据控制全身运动轨迹 -
跨模态融合:在DiT模块中通过交叉注意力机制整合面部与身体控制信号
2. 多尺度渐进训练:适应全场景人像生成
-
分辨率分级训练:采用256×256至1024×1024多级分辨率数据集 -
尺度感知学习:通过数据增强模拟肖像、上半身、全身等不同构图 -
动态注意力分配:根据输入尺度自动调整面部/身体的关注权重
3. 长期时间一致性保障
-
互补视觉参考:引入多帧参考图像补充运动过程中的遮挡区域细节 -
3D VAE视频编码:对输入视频片段进行时空联合编码 -
身份保持损失函数:通过对比学习强化角色身份特征
实际应用场景与功能亮点
多样化风格支持
-
可适配卡通、写实、艺术化等不同视觉风格 -
支持多语言口型同步(中/英/日等) -
兼容第三方骨骼动画数据输入
精细化控制能力
-
局部动作迁移:仅转移面部表情或头部运动 -
骨骼长度调节:根据角色体型自动适配动作幅度 -
视角动态调整:支持0°-180°头部转向控制
工业级鲁棒性
-
处理复杂动作时画面稳定性提升43%(对比SOTA) -
身份保持相似度达98.7%(CelebA-HQ测试集) -
支持长达30秒的连续动作生成
技术对比:超越现有SOTA方案
| 指标 | DreamActor-M1 | Method A | Method B |
|---|---|---|---|
| 面部表情精度 | 92.4% | 85.1% | 79.3% |
| 时间一致性(PSNR) | 34.6dB | 29.8dB | 27.1dB |
| 全身动作自然度 | 9.2/10 | 7.8/10 | 6.5/10 |
| 跨尺度生成成功率 | 96% | 82% | 68% |
测试数据基于Bytedance内部评测集
典型应用案例
案例1:影视级数字人动画
-
输入:演员静态剧照 + 动作捕捉数据 -
输出:可直接用于影视制作的4K分辨率动画序列 -
优势:避免传统3D建模的耗时流程
案例2:虚拟直播解决方案
-
支持实时面部表情驱动(延迟<200ms) -
自动优化光照一致性 -
提供SDK接入主流直播平台
案例3:个性化短视频创作
-
用户上传自拍照即可生成舞蹈视频 -
内置20+预设动作模板 -
支持抖音/快手等平台特效格式导出
技术实现细节揭秘
DiT架构优化
-
通道维度融合:将姿势潜码与噪声潜码沿通道维度拼接 -
双分支权重共享:参考图像分支与噪声分支共享DiT权重 -
分层注意力机制: -
面部注意力(Face Attn):处理表情特征 -
自注意力(Self Attn):维护时序连贯 -
参考注意力(Ref Attn):注入外观细节
-
训练策略
-
两阶段训练流程: -
基础能力构建:500万视频片段训练 -
精细化调优:100万高质量影视数据集
-
-
混合监督信号: -
像素级L1损失 -
感知损失(VGG-19特征匹配) -
对抗训练(基于StyleGAN2判别器)
-
未来发展方向
-
多角色交互:支持场景内多人互动动画生成 -
物理引擎集成:实现布料模拟等物理效果 -
跨模态扩展:结合文本描述生成定制化动作
论文信息
@misc{luo2025dreamactorm1holisticexpressiverobust,
title={DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance},
author={Yuxuan Luo and Zhengkun Rong and Lizhen Wang and Longhao Zhang and Tianshu Hu and Yongming Zhu},
year={2025},
eprint={2504.01724},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.01724},
}
立即访问项目主页获取更多技术细节与演示视频
关注「Bytedance Intelligent Creation」获取最新研究动态