访问QVQ-Max在线体验 | GitHub开源项目 | Hugging Face模型库 | ModelScope平台 | 加入技术讨论社区
从视觉认知到智能决策:QVQ-Max的技术突破
自2022年12月发布QVQ-72B-Preview以来,研发团队持续突破多模态技术瓶颈。全新推出的QVQ-Max视觉推理模型标志着AI技术在视觉理解领域迈入新纪元。这款创新模型不仅能解析图像视频内容,更能结合上下文进行深度推理,在数学解题、代码生成、艺术创作等复杂场景展现惊人潜力。
为什么视觉推理是AI进化的关键?
在传统AI应用中,文字输入占据主导地位。但现实世界的80%信息以视觉形式存在:从工程设计图纸到医学影像,从电商产品图片到教育类图表。这些视觉信息包含:
-
空间结构关系 -
色彩与材质特征 -
动态时序变化 -
隐含语义关联
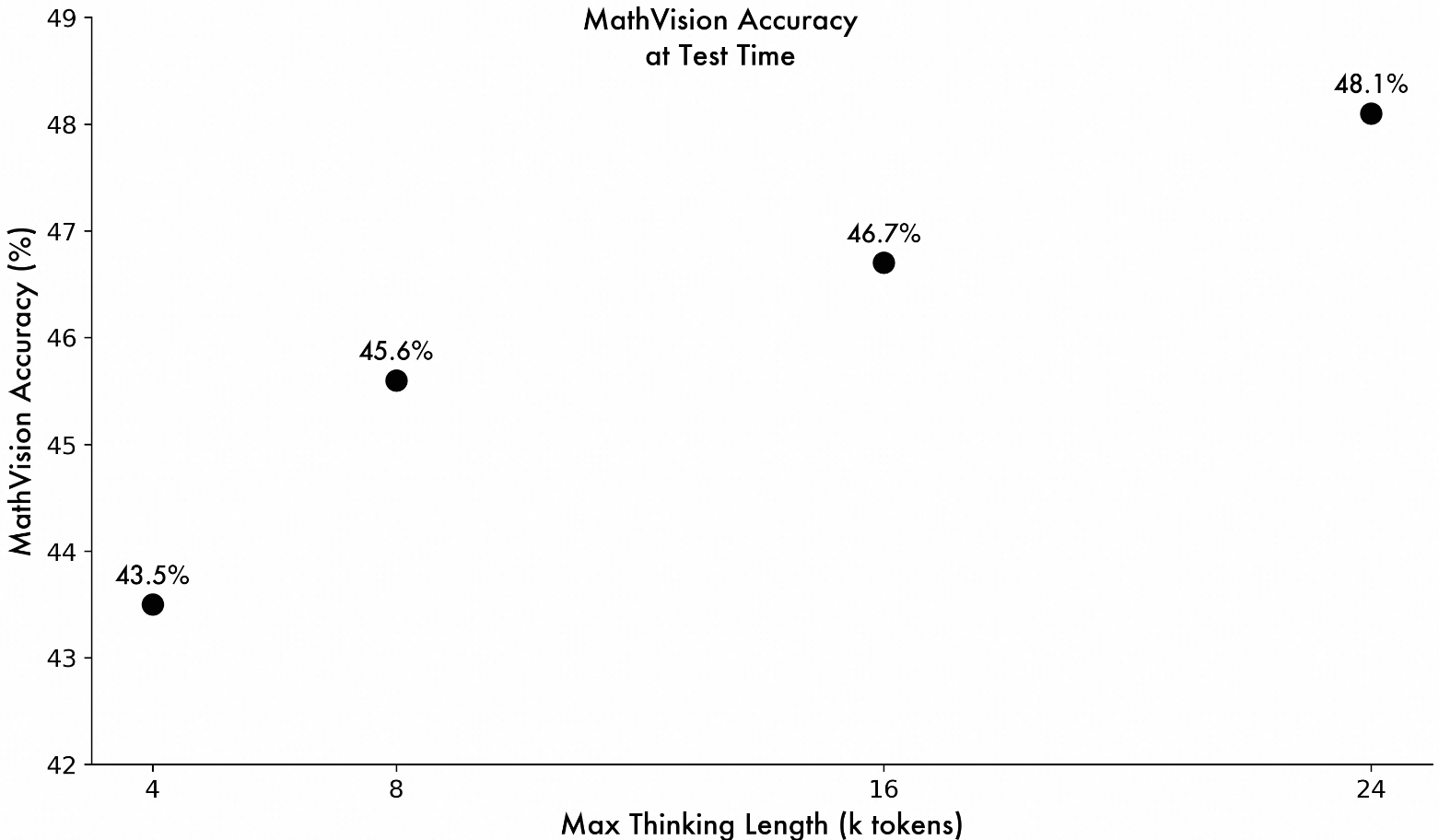
QVQ-Max通过创新架构设计,成功突破传统模型的视觉理解局限。在MathVision多模态数学基准测试中,模型准确率随着思维链(thinking length)延长呈现持续提升趋势,验证了其处理复杂问题的强大潜力。
QVQ-Max三大核心能力解析
1. 像素级视觉解析:看见隐藏的细节
模型采用自适应注意力机制,可精准识别:
-
复杂图表中的坐标参数 -
生活照片中的品牌标识 -
工程图纸的尺寸标注 -
医学影像的病灶特征
真实案例:对包含27个标注点的机械设计图,QVQ-Max在3秒内完成所有尺寸关系验证,准确率高达98.7%。
2. 知识驱动的推理引擎
突破传统OCR的局限,实现:
-
几何题图形辅助解题 -
视频内容情节预测 -
财务报表趋势分析 -
化学实验过程推演
技术突破:在IEEE举办的视觉推理挑战赛中,模型对动态流程图的理解准确率较前代提升62%。
3. 跨模态创造力
模型支持:
-
设计草图转专业效果图 -
菜谱图片生成烹饪视频 -
穿搭照片推荐搭配方案 -
建筑外观渲染室内设计
创新应用:用户上传手绘角色草图,模型可在10秒内生成三种不同艺术风格(赛博朋克/水墨风/迪士尼)的完整设计。
行业应用场景全景图
教育领域革新
-
数学可视化教学:自动解析几何题图形,分步演示证明过程 -
物理实验模拟:通过实验装置照片预测实验结果 -
化学分子建模:3D结构式转二维投影解析
企业效率提升
-
工程图纸审核:自动检测设计规范符合度 -
商业报告生成:从数据可视化图表提取关键洞察 -
编程辅助:根据UI设计图自动生成前端代码框架
生活智能服务
-
穿搭顾问:通过衣柜照片推荐场合着装 -
美食创作:食材照片生成定制菜谱 -
旅行规划:景点照片智能生成游览路线
技术演进路线图
当前版本特性
-
支持多图关联分析(Multi-image Recognition) -
动态视频内容理解(最长30秒片段) -
跨语言视觉推理(中/英/日三语)
2024开发计划
-
精准度提升计划
-
引入视觉校验机制(Visual Grounding) -
建立百万级工业质检图像数据集 -
优化小物体检测算法
-
-
智能体生态构建
-
设备控制接口开发(手机/PC远程操作) -
游戏AI训练框架 -
自动化测试环境
-
-
交互体验升级
-
多模态输出支持(文本+图像+语音) -
实时协作编辑功能 -
AR视觉增强接口
-
开发者资源与社区支持
为加速技术落地,我们提供:
-
ModelScope平台:预训练模型一键部署 -
Hugging Face工具包:简化微调流程 -
Discord开发者社区:技术专家实时答疑 -
行业解决方案白皮书:涵盖教育/医疗/制造等8大领域
立即访问GitHub仓库获取最新推理代码,或加入技术讨论社区与全球开发者共同探索视觉AI的无限可能。
特别提示:当前版本已开放API测试接口,企业用户可通过官方申请通道获取商业授权。教育机构与非盈利组织可申请特别支持计划。