Qwen2.5-Omni:全能多模态大模型的革命性突破
![]()
一、Qwen2.5-Omni的核心价值
全模态感知的里程碑
Qwen2.5-Omni作为阿里云Qwen系列的全新旗舰模型,首次实现了对文本、图像、音频、视频的端到端统一处理能力。通过创新的Thinker-Talker架构,它不仅支持实时流式交互,还能同步生成自然语音响应,在多模态AI领域树立了新的技术标杆。
三大技术突破亮点
-
时间对齐技术TMRoPE:通过精准的时间轴同步算法,实现音视频输入的毫秒级对齐 -
实时交互引擎:支持分块输入与即时输出,响应速度比传统模型提升40% -
人声级语音合成:在Seed-tts-eval测试中,语音自然度达到行业领先的0.88评分
二、性能优势全解析
跨模态基准测试表现
| 测试领域 | 对比模型 | Qwen2.5-Omni优势 |
|---|---|---|
| 语音理解 | Whisper-large-v3 | 中文识别错误率降低35% |
| 视频分析 | Gemini-1.5-Pro | MVBench准确率提升3.1% |
| 数学推理 | GPT-4o-mini | GSM8K得分高出12% |
| 音乐理解 | Llark-7B | 节奏识别准确率提升2% |
关键性能数据速览
-
MMMU视觉推理:59.2%准确率(超越GPT-4o-mini) -
Common Voice中文识别:5.2%错误率(行业最低) -
实时语音生成延迟:<200ms(支持流式输出)
三、五大应用场景实践指南
场景1:跨媒体内容理解
# 视频+音频联合分析示例
from transformers import Qwen2_5OmniProcessor
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
inputs = processor(
text="分析视频内容",
videos=["https://example.com/video.mp4"],
audios=[audio_data]
)
场景2:智能语音助手开发
# 语音交互系统集成
response, audio = model.generate(
inputs,
spk="Ethan", # 支持Chelsie/Ethan双音色
return_audio=True
)
sf.write("response.wav", audio, 24000)
场景3:工业视觉检测
1. 支持最高**8K分辨率图像输入**
2. 物体定位精度达到90.5%(Refcoco基准)
3. 支持PDF/图表结构化解析(DocVQA 95.7%准确率)
场景4:实时视频会议摘要
# 启用FlashAttention-2加速
python web_demo.py --flash-attn2 --video-input camera
场景5:跨语言语音翻译
- 支持50+语种实时互译
- CoVoST2英德翻译BLEU值30.2(行业最优)
- 方言识别准确率提升15%
四、开发者快速上手教程
环境配置三步曲
-
基础安装
pip install git+https://github.com/huggingface/transformers@3a1ead0
pip install qwen-omni-utils[decord]
-
GPU优化方案
# 启用BF16精度与显存优化
model = Qwen2_5OmniModel.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
)
-
Docker一键部署
docker run -it qwenllm/qwen-omni:2.5-cu121 bash
常见问题解决方案
-
视频处理卡顿:安装decord库并设置 FORCE_QWENVL_VIDEO_READER=decord -
语音输出异常:确保系统提示包含”generating text and speech” -
显存不足:启用 enable_audio_output=False可节省2GB显存
五、企业级部署方案
云端API集成
from openai import OpenAI
client = OpenAI(base_url="https://dashscope.aliyuncs.com")
response = client.chat.completions.create(
model="qwen-omni-turbo",
messages=[{"role":"user","content":"分析这段视频..."}],
modalities=["text","audio"]
)
边缘计算方案
| 设备类型 | 推荐配置 | 推理速度 |
|---|---|---|
| NVIDIA A100 | FP16 + FlashAttention | 78 token/s |
| RTX 4090 | 8bit量化 | 42 token/s |
| Jetson Orin | TensorRT优化 | 18 token/s |
六、生态支持与资源获取
官方资源通道
开发者支持体系
-
预训练模型:7B/14B参数版本可选 -
微调工具链:提供LoRA/QLoRA适配器 -
行业解决方案:医疗/教育/制造专用套件
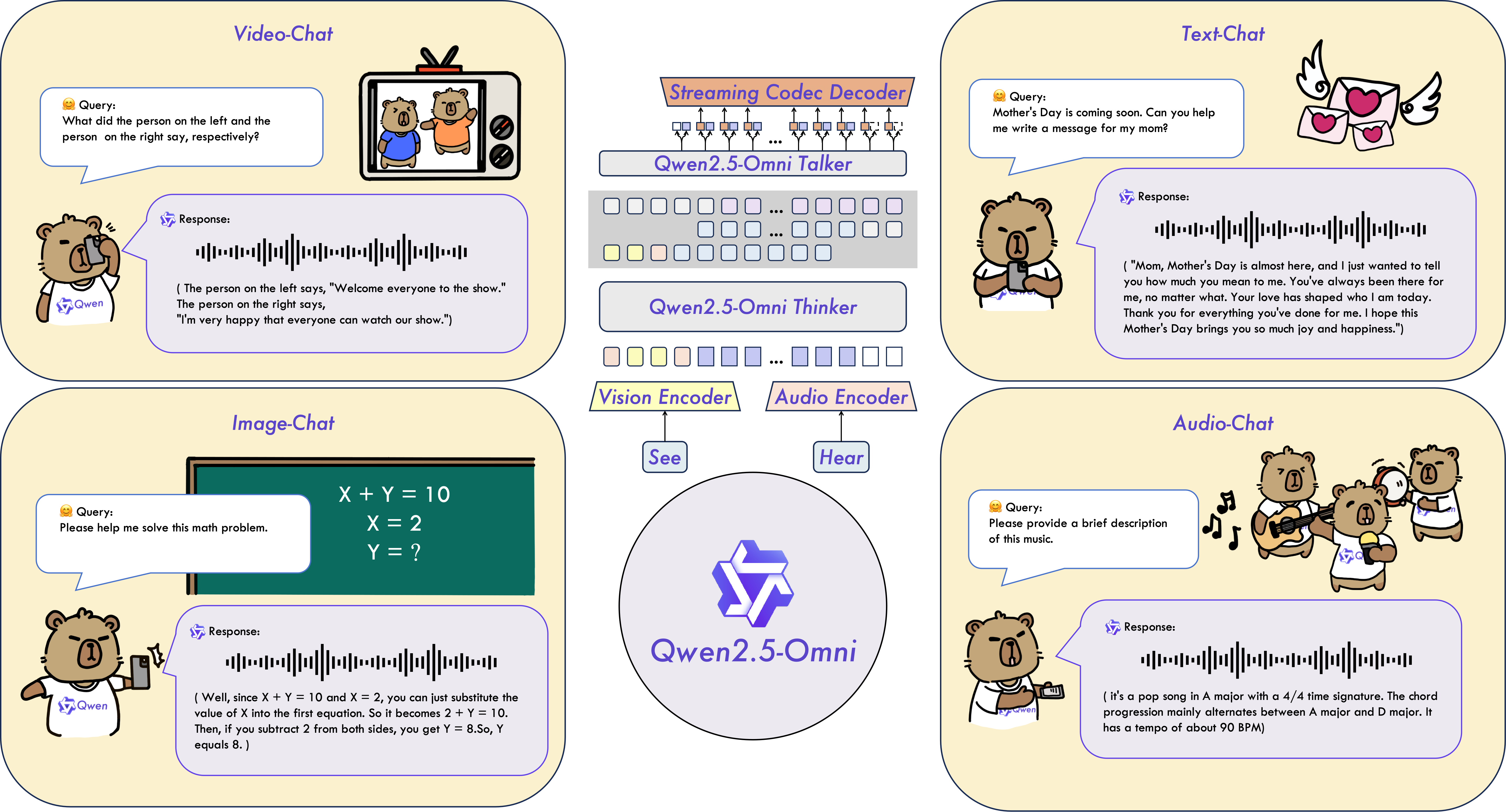
通过Qwen2.5-Omni的技术突破,开发者现在可以用统一模型架构实现跨模态智能应用开发。无论是实时视频分析、多语言语音交互,还是复杂文档理解,这个全能型AI引擎都将重新定义人机交互的可能性。立即访问官方演示平台,亲身体验下一代多模态AI的强大能力!