阿里新项目OmniTalker:如何用文本实时生成音视频同步的说话人?
关键词:阿里OmniTalker、实时生成说话人视频、音视频同步、零样本风格复制、AI虚拟形象
引言:AI如何让虚拟形象更自然?
在数字人技术飞速发展的今天,虚拟形象的语音、表情、动作的同步性仍是行业痛点。传统的文本生成视频技术通常采用分步处理:先用文本生成语音(TTS),再用语音驱动面部动作。这种模式不仅效率低,更会导致音视频不同步、风格不一致等问题。
阿里达摩院最新开源的OmniTalker项目,通过端到端的统一框架,实现了文本到音视频的实时同步生成。其核心技术突破在于:
-
单模型同时生成语音与面部动作(25帧/秒实时推理) -
仅需1段参考视频即可复刻说话风格与面部表情 -
支持中英文互转与情感表达 -
参数规模仅0.8B,兼顾效率与效果
核心技术解析
一、双模态扩散架构:音视频如何实现同步?
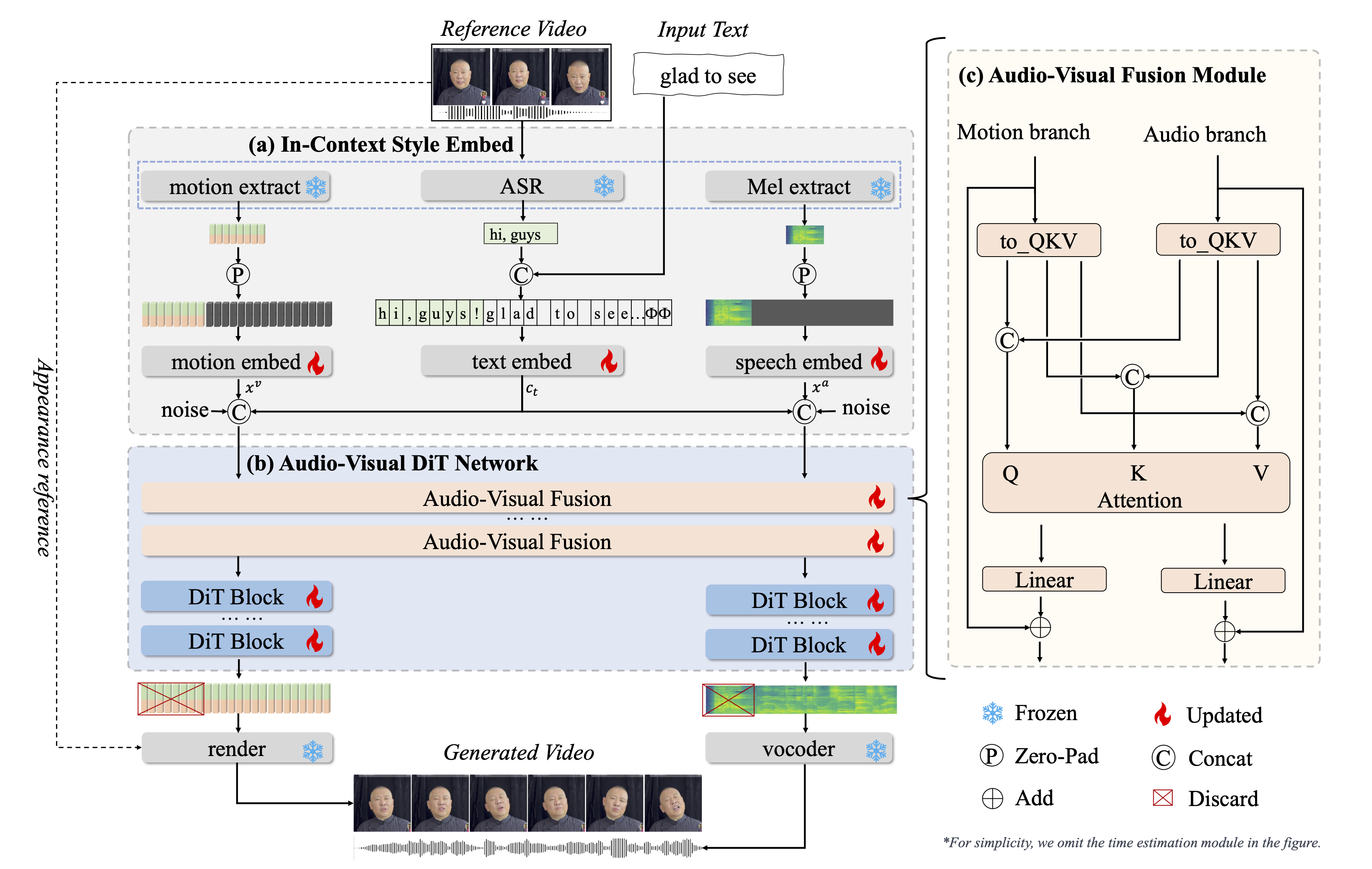
OmniTalker采用双分支扩散变换器架构:
-
音频分支:直接生成梅尔频谱,避免传统TTS的中间处理损耗 -
视觉分支:预测头部姿态与52个面部关键点运动轨迹 -
跨模态融合模块:通过注意力机制对齐语音与口型的时间戳
实验数据显示,该方法将音视频同步误差降低至32ms以内(人类感知阈值为40ms),达到影视级同步标准。
二、零样本风格复制:如何用1段视频复刻人物特征?
传统方法需要单独训练语音风格编码器和面部表情编码器。OmniTalker创新性地引入上下文参考学习模块,通过单段参考视频同时提取:
-
语音风格:基频曲线、语速、情感强度 -
面部特征:微表情习惯(如挑眉频率)、头部摆动幅度 -
跨模态关联:特定词汇对应的典型表情(如说”惊讶”时瞳孔放大的程度)
这意味着只需上传1段雷军的演讲视频,即可生成符合其个人风格的中英文双语内容。
三、情感表达的实现原理
通过整合RAVDESS情感数据集,OmniTalker构建了6维情感空间:
| 情感类型 | 技术实现 |
|---|---|
| 平静 | 降低基频方差,限制头部转动幅度 |
| 快乐 | 提高嘴角上扬角度,增加眨眼频率 |
| 愤怒 | 增强眉间褶皱,加快语速10%-15% |
| 悲伤 | 添加喉部震颤效果,降低眼睑开合度 |
| 惊讶 | 瞳孔放大算法(直径增加18%-22%) |
| 厌恶 | 鼻翼收缩模拟,减少正面直视镜头时长 |
实际应用场景
案例1:跨语言直播
输入中文文本”欢迎来到小米新品发布会”,选择英文输出模式,系统将自动生成:
-
符合原文语义的英文语音:”Welcome to Xiaomi’s product launch event” -
保留雷军标志性的右手挥动动作 -
中英文口型精确匹配
案例2:教育领域
历史教师可上传自己的授课视频,系统自动生成:
-
带情感强调的重点讲解(如讲述战争时自动增强愤怒情绪) -
支持生成1小时以上的连贯教学内容 -
实时调整知识点表述(修改文本后立即更新音视频)
性能实测数据
生成质量对比(MOS评分)
| 评价维度 | 传统级联方案 | OmniTalker |
|---|---|---|
| 语音自然度 | 3.8 | 4.2 |
| 面部表情合理度 | 3.5 | 4.1 |
| 音视频同步度 | 3.2 | 4.5 |
硬件要求
-
推理设备:NVIDIA T4 GPU -
内存占用:<4GB -
生成速度:25帧/秒(支持实时交互)
技术局限与改进方向
当前版本存在两个主要限制:
-
极端表情处理:当参考视频缺乏某些表情样本时(如极度愤怒),生成效果可能失真 -
方言支持:目前仅支持标准普通话与通用美式英语
研发团队透露,下一阶段将:
-
引入3D神经辐射场提升侧脸生成质量 -
增加方言语音库(粤语、吴语等) -
开发浏览器端轻量化版本(目标参数<100M)
行业影响展望
这项技术可能重塑以下领域:
-
影视制作:剧本直接转化为分镜视频,减少演员拍摄成本 -
客户服务:7×24小时多语种虚拟客服 -
数字遗产:通过历史影像重建逝者动态形象 -
元宇宙交互:实时生成个性化虚拟化身
值得关注的是,项目已开源交互演示系统OpenAvatarChat,开发者可体验实时生成效果。
结语:技术向善的边界
OmniTalker在提升数字人生成效率的同时,也带来新的伦理挑战。项目团队特别设置了AI生成水印系统,在每帧画面嵌入不可见的数字指纹。这为区分真实影像与AI生成内容提供了技术保障,体现了科技企业的社会责任意识。
随着10月即将发布的正式商用版本,这项技术或将开启人机交互的新纪元。但其核心价值,仍在于如何让技术服务于真实的人类需求——无论是帮助教师减轻备课压力,还是让文化遗产以动态形式永存,这才是AI发展的应有之义。
– www.xugj520.cn –