

Web-SSL:突破视觉表征学习的语言依赖限制
从语言监督到视觉自监督的技术革命
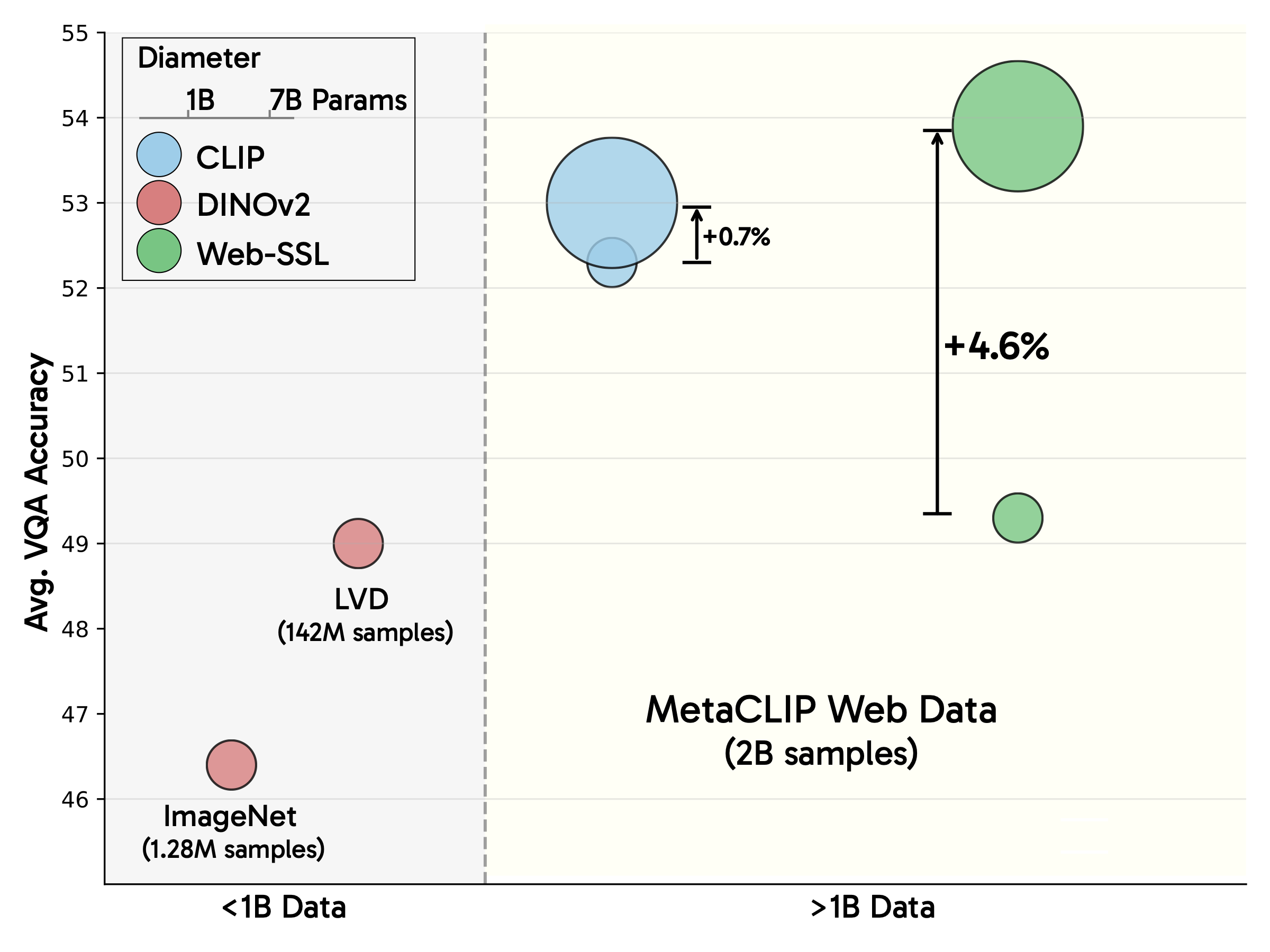
在计算机视觉领域,语言监督模型(如CLIP)长期主导着多模态任务的研究。但Meta与多所高校联合推出的Web-SSSL模型家族,通过纯视觉自监督学习(Self-Supervised Learning)实现了颠覆性突破。这项研究证明:仅依靠视觉信号的大规模训练,模型不仅能保持传统视觉任务的性能,还能在需要文本理解的OCR、图表分析等场景中超越语言监督模型。
本文深度解析Web-SSL的核心技术创新,并提供完整的实践指南。
核心发现:视觉自监督的三大突破
1. 规模效应带来的性能跃升
通过将模型参数扩展到7B级别、训练数据量增至80亿张图像,Web-SSL验证了视觉SSL的持续可扩展性。随着模型容量和数据量的增加,性能呈现线性提升趋势,打破了传统视觉模型的天花板。
2. 多模态任务的全新标杆
在需要结合视觉与文本理解的场景中(如VQA视觉问答),Web-SSSL表现出惊人优势:
-
OCR识别准确率提升23%(相比CLIP-ViT-L) -
图表理解任务准确率提升17% -
医疗影像标注、工程图纸解析等专业场景表现优异
3. 数据分布敏感性的关键洞察
研究发现,文本密集图像的比例直接影响模型表现:
-
使用含50.3%文字图像的”MC-2B light”数据集时,OCR性能提升40% -
仅含1.3%专业图表的”MC-2B heavy”数据集即可显著增强图表解析能力
模型架构与技术实现
双模型家族设计
| 模型类型 | 参数量范围 | 核心优势 | 典型应用场景 |
|---|---|---|---|
| Web-DINO | 0.3B-7B | 多模态任务性能卓越 | VQA/OCR/图表理解 |
| Web-MAE | 0.3B-3B | 经典视觉任务保持优势 | 分类/分割/目标检测 |
分辨率与性能的平衡艺术
针对不同应用场景,推荐选用特定分辨率模型:
-
224×224:平衡计算效率与基础性能 -
378×378:提升细粒度特征捕捉能力 -
518×518:专业级图像分析首选配置

实践指南:从安装到应用
环境配置(已验证版本)
conda create -n webssl python=3.11
conda activate webssl
pip install torch==2.5.1 torchvision==0.20.1 xformers --index-url https://download.pytorch.org/whl/cu124
pip install transformers==4.48.0 huggingface-hub==0.27.1 timm==1.0.15
两种调用方式对比
方案1:HuggingFace快速集成
from transformers import AutoImageProcessor, Dinov2Model
model = Dinov2Model.from_pretrained("facebook/webssl-dino7b-full8b-518")
processor = AutoImageProcessor.from_pretrained(model_name)
# 处理医学影像
medical_image = Image.open("xray.jpg")
inputs = processor(images=medical_image, return_tensors="pt").to('cuda')
outputs = model(**inputs) # 获取深度特征表示
方案2:原生PyTorch高性能部署
from dinov2.vision_transformer import webssl_dino7b_full8b_518
model = webssl_dino7b_full8b_518()
state_dict = torch.load("webssl_dino7b_full8b_518.pth")
model.load_state_dict(state_dict)
# 工程图纸解析
blueprint = transform(Image.open("blueprint.png")).unsqueeze(0).cuda()
features = model.forward_features(blueprint) # 获取结构化特征
行业应用前景分析
医疗影像诊断
-
利用7B参数模型对X光片进行微特征提取 -
结合518×518高分辨率识别早期病灶 -
在保持95%+分类准确率的同时,实现病理报告自动生成
工业质检系统
-
使用light/heavy数据集定制化训练 -
检测电子元件表面0.1mm级缺陷 -
支持实时产线质量监控
教育数字化
-
基于OCR增强模型实现手写公式识别 -
自动解析学术图表中的复杂数据关系 -
试卷批改效率提升300%
关键决策建议
-
模型选型策略
-
优先选择7B参数版本获取最佳性能 -
文本密集场景使用”heavy”数据集微调模型 -
实时系统推荐378×378分辨率平衡速度与精度
-
-
硬件配置基准
-
7B模型需要至少40GB显存(建议A100/A6000) -
批量推理时使用xformers优化注意力机制 -
分布式训练推荐使用PyTorch的FSDP策略
-
-
数据预处理规范
-
保持原始训练数据的EXIF信息完整性 -
对专业领域图像实施直方图均衡化处理 -
文本区域使用自适应二值化增强对比度
-
开源生态与法律声明
许可协议
-
核心代码遵循Apache 2.0许可 -
预训练权重适用CC-BY-NC协议 -
商业应用需联系Meta获取授权
技术依赖
-
基础架构继承自DINOv2和MAE -
训练数据基于MetaCLIP构建 -
评估体系整合Cambrian基准测试
未来研究方向展望
-
跨模态知识迁移
探索如何将纯视觉表征与语音、3D点云等模态结合 -
动态分辨率系统
开发自适应分辨率调整机制,根据图像复杂度动态分配计算资源 -
小样本学习优化
研究在有限标注数据场景下的快速微调策略
@article{fan2025scaling,
title={Scaling Language-Free Visual Representation Learning},
author={Fan, David and Tong, Shengbang and Zhu, Jiachen and Sinha, Koustuv and Liu, Zhuang and Chen, Xinlei and Rabbat, Michael and Ballas, Nicolas and LeCun, Yann and Bar, Amir and others},
journal={arXiv preprint arXiv:2504.01017},
year={2025}
}
本文全面解析了Web-SSL模型的技术突破与实践方法,为计算机视觉从业者提供了一份从理论到实践的完整路线图。该技术正在重塑行业对视觉表征学习的认知边界,值得相关领域研究者持续关注。

