

Web-SSL: Redefining Visual Representation Learning Without Language Supervision
The Shift from Language-Dependent to Vision-Only Models
In the realm of computer vision, language-supervised models like CLIP have long dominated multimodal research. However, the Web-SSL model family, developed through a collaboration between Meta and leading universities, achieves groundbreaking results using purely visual self-supervised learning (SSL). This research demonstrates that large-scale vision-only training can not only match traditional vision task performance but also surpass language-supervised models in text-rich scenarios like OCR and chart understanding.
This article explores Web-SSL’s technical innovations and provides actionable implementation guidelines.
Key Breakthroughs: Three Pillars of Visual SSL
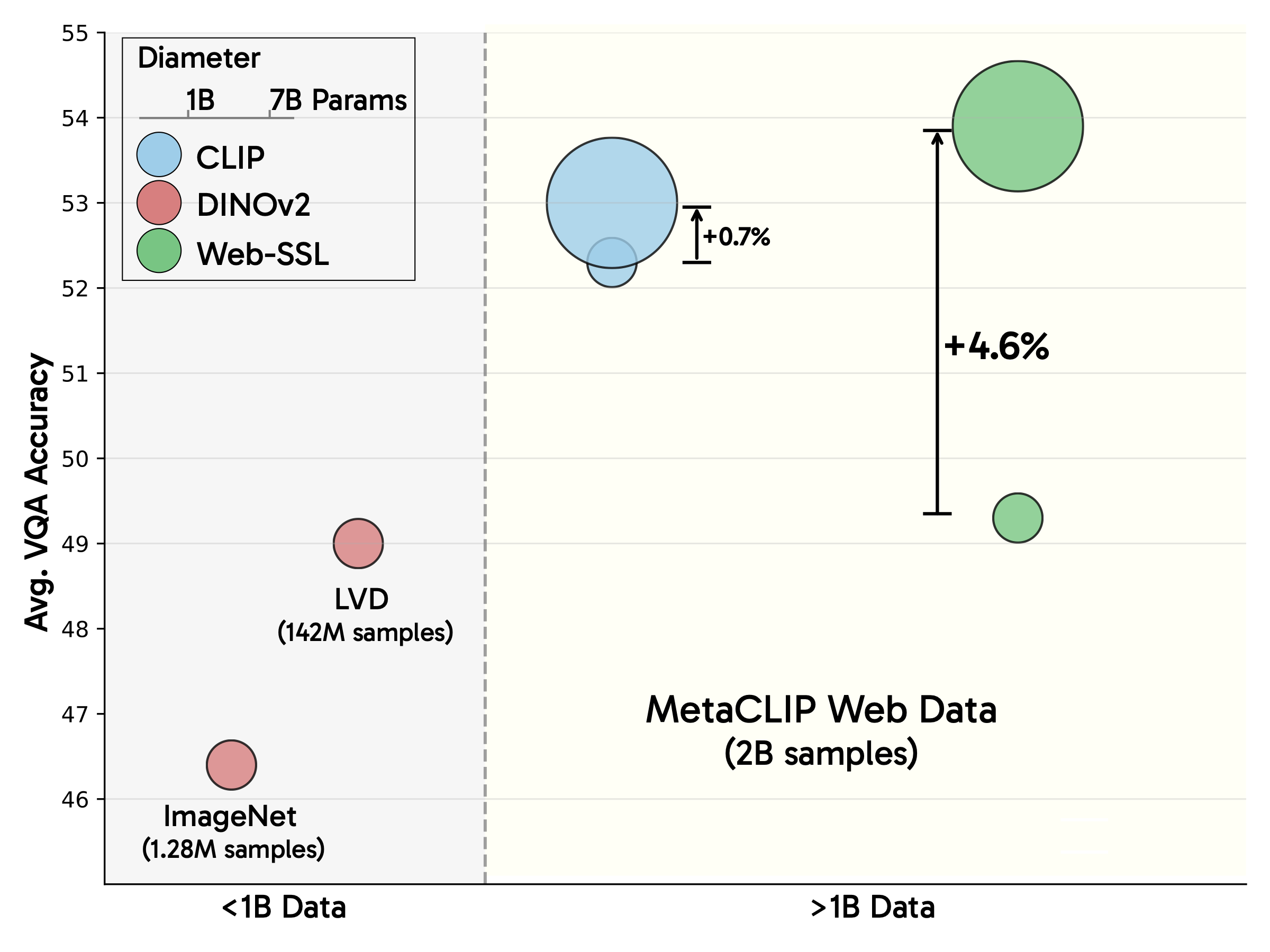
1. Scalability-Driven Performance Gains
By scaling model parameters to 7B and training on 8 billion images, Web-SSL validates the continuous scalability of visual SSL. Performance scales linearly with model size and data volume, shattering previous limitations of vision models.
2. New Benchmarks for Multimodal Tasks
In scenarios requiring visual-textual understanding (e.g., visual question answering):
-
OCR accuracy improves by 23% (vs. CLIP-ViT-L) -
Chart understanding accuracy increases by 17% -
Superior performance in specialized domains like medical imaging and technical diagram analysis
3. Data Distribution Sensitivity
Critical insights into dataset design:
-
Using the “MC-2B light” dataset (50.3% text-rich images) boosts OCR performance by 40% -
The “MC-2B heavy” subset (1.3% charts/documents) significantly enhances diagram parsing
Architecture & Technical Implementation
Dual Model Family Design
| Model Type | Parameter Range | Core Strength | Ideal Use Cases |
|---|---|---|---|
| Web-DINO | 0.3B-7B | Multimodal excellence | VQA/OCR/Chart analysis |
| Web-MAE | 0.3B-3B | Classic vision task parity | Classification/Segmentation |
Resolution Optimization Guide
| Resolution | Compute Efficiency | Use Case Recommendation |
|---|---|---|
| 224×224 | ⭐⭐⭐⭐ | General-purpose inference |
| 378×378 | ⭐⭐⭐ | Fine-grained feature extraction |
| 518×518 | ⭐⭐ | Professional-grade analysis |

Implementation Guide: From Setup to Deployment
Verified Environment Configuration
conda create -n webssl python=3.11
conda activate webssl
pip install torch==2.5.1 torchvision==0.20.1 xformers --index-url https://download.pytorch.org/whl/cu124
pip install transformers==4.48.0 huggingface-hub==0.27.1 timm==1.0.15
Two Deployment Strategies
Option 1: HuggingFace Integration
from transformers import AutoImageProcessor, Dinov2Model
model = Dinov2Model.from_pretrained("facebook/webssl-dino7b-full8b-518")
processor = AutoImageProcessor.from_pretrained(model_name)
# Medical image processing
medical_image = Image.open("xray.jpg")
inputs = processor(images=medical_image, return_tensors="pt").to('cuda')
outputs = model(**inputs) # Extract deep features
Option 2: Native PyTorch Deployment
from dinov2.vision_transformer import webssl_dino7b_full8b_518
model = webssl_dino7b_full8b_518()
state_dict = torch.load("webssl_dino7b_full8b_518.pth")
model.load_state_dict(state_dict)
# Engineering blueprint analysis
blueprint = transform(Image.open("blueprint.png")).unsqueeze(0).cuda()
features = model.forward_features(blueprint) # Structured feature extraction
Industry Applications & Use Cases
Medical Imaging Diagnosis
-
7B model for micro-feature extraction in X-rays -
518×518 resolution for early pathology detection -
Automated report generation with >95% classification accuracy
Industrial Quality Control
-
Custom training with light/heavy datasets -
Detection of 0.1mm-level component defects -
Real-time production line monitoring
Educational Digitization
-
Enhanced OCR for handwritten formula recognition -
Automated analysis of academic charts -
300% efficiency gain in test grading
Strategic Recommendations
-
Model Selection
-
Prioritize 7B models for peak performance -
Use “heavy” datasets for text-dense scenarios -
Choose 378×378 resolution for real-time systems
-
-
Hardware Requirements
-
40GB+ VRAM for 7B models (A100/A6000 recommended) -
Optimize attention with xformers -
Use PyTorch FSDP for distributed training
-
-
Data Preprocessing
-
Preserve EXIF metadata -
Apply histogram equalization for domain-specific images -
Enhance text regions with adaptive binarization
-
Licensing & Ecosystem
Open-Source Compliance
-
Core code: Apache 2.0 License -
Pretrained weights: CC-BY-NC -
Commercial use requires Meta authorization
Technical Dependencies
-
Built upon DINOv2 and MAE architectures -
Trained on MetaCLIP datasets -
Evaluated using Cambrian benchmarks
Future Research Directions
-
Cross-Modal Knowledge Transfer
Explore integration with audio, 3D point clouds, and other modalities -
Dynamic Resolution Systems
Develop adaptive resolution allocation based on image complexity -
Few-Shot Learning Optimization
Investigate efficient fine-tuning strategies for low-data scenarios
@article{fan2025scaling,
title={Scaling Language-Free Visual Representation Learning},
author={Fan, David and Tong, Shengbang and Zhu, Jiachen and Sinha, Koustuv and Liu, Zhuang and Chen, Xinlei and Rabbat, Michael and Ballas, Nicolas and LeCun, Yann and Bar, Amir and others},
journal={arXiv preprint arXiv:2504.01017},
year={2025}
}
This comprehensive analysis of Web-SSL provides researchers and practitioners with both theoretical insights and practical implementation strategies. The technology is reshaping boundaries in visual representation learning, warranting close attention from the computer vision community.

