
Comparing Unsloth and PEFT Features
Explore the key differences between Unsloth and PEFT.
Features | Unsloth | PEFT |
|---|---|---|
Performance Speed | Achieves 2x faster performance. | Focuses on parameter-efficient fine-tuning. |
Memory Usage | Uses 70% less memory. | Minimizes resource requirements. |
Ease of Use | User-friendly notebooks for beginners. | Integrates with Hugging Face ecosystem. |
Model Support | Supports various advanced models. | Compatible with Hugging Face models. |
Scalability | Optimized for large datasets. | Efficient on consumer-grade hardware. |
Cost Efficiency | Reduces hardware costs significantly. | Saves on computational resources. |
Long-Context Reasoning | Excels in deep contextual understanding. | Less focus on long-context tasks. |
Installation Process | Simple installation via pip. | Requires Hugging Face setup. |
Fine-tuning large language models can be challenging, especially when balancing performance and resource efficiency. PEFT Unsloth Parameter-Efficient Fine-Tuning addresses this issue with innovative approaches. Unsloth emphasizes speed and memory optimization, delivering faster processing and reduced memory usage. On the other hand, PEFT focuses on parameter-efficient fine-tuning, enabling model adaptation with minimal adjustments. For example, methods like LoRA in PEFT achieve high throughput while maintaining low memory usage. These tools cater to diverse needs, whether you prioritize rapid execution or operate in resource-constrained environments. Selecting between them depends on your project’s unique requirements.
Key Takeaways
Unsloth is fast and uses less memory. It works up to 2x faster and saves 70% memory, making it great for tasks with limited resources.
PEFT fine-tunes models with small changes. It trains fewer parameters, cutting down costs and working well on regular computers.
Use Unsloth for quick tasks and long-context thinking. PEFT is better for things like summarizing text or finding emotions in resource-limited setups.
You can combine both tools for the best results. Use Unsloth for speed and PEFT for tuning, saving time and resources.
Unsloth is easy to use with beginner-friendly guides. PEFT works well with Hugging Face tools, helping different types of users.
Overview of Unsloth
What is Unsloth?
Unsloth is a state-of-the-art tool designed to fine-tune large language models like Llama 3.3, Mistral, and DeepSeek-R1. It prioritizes speed and memory efficiency, enabling you to achieve faster performance while using significantly less memory. This makes it an excellent choice for developers, researchers, and AI enthusiasts who want to optimize their machine learning projects without overburdening their hardware.
The platform is user-friendly, offering beginner-friendly notebooks where you can add datasets and run models effortlessly. It supports a wide range of models, including Llama 3.2 and Phi-4, ensuring compatibility with the latest advancements in AI. Unsloth also excels in long-context reasoning, making it ideal for tasks requiring deep understanding and contextual awareness.
Key Features of Unsloth
Unsloth offers several standout features that set it apart from other fine-tuning tools:
Performance and Memory Efficiency: Achieve up to 2x faster performance while reducing memory usage by 70%.
Wide Model Support: Compatible with models like Llama 3.2, Qwen 2.5, and Phi-4.
Long-Context Reasoning: Optimized for tasks requiring deep contextual understanding.
Dynamic Quantization: Balances accuracy and memory usage effectively.
Ease of Use: Simple installation via pip and compatibility with Linux and Windows environments.
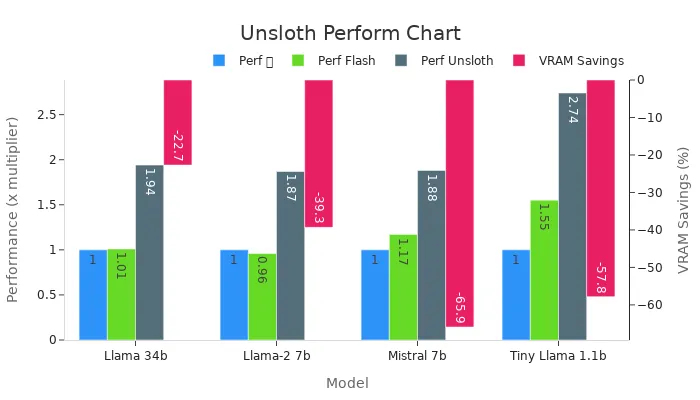
The following table highlights Unsloth’s performance metrics compared to other methods:
Model | Dataset | Performance (🤗) | Performance (🤗 + Flash Attention 2) | Performance (🦥 Unsloth) | VRAM Savings |
|---|---|---|---|---|---|
Llama 34b | Slim Orca | 1x | 1.01x | 1.94x | -22.7% |
Llama-2 7b | Slim Orca | 1x | 0.96x | 1.87x | -39.3% |
Mistral 7b | Slim Orca | 1x | 1.17x | 1.88x | -65.9% |
Tiny Llama 1.1b | 1x | 1.55x | 2.74x | -57.8% |
Purpose and Applications of Unsloth
Unsloth is designed to address the challenges of fine-tuning large language models. It is perfect for tasks requiring high-speed processing and efficient memory usage. You can use it for conversational AI, reasoning tasks, and other applications that demand long-context understanding. Its compatibility with NVIDIA GPUs ensures accessibility for a wide range of users, from researchers to developers.
The tool also supports advanced reinforcement learning techniques and vision models, making it versatile for various machine learning projects. Whether you are working on a resource-constrained system or need to fine-tune models quickly, Unsloth provides a reliable solution.
By combining speed, memory efficiency, and ease of use, Unsloth stands out as a comprehensive tool for PEFT Unsloth Parameter-Efficient Fine-Tuning.
Overview of PEFT
What is PEFT?
PEFT, or Parameter-Efficient Fine-Tuning, is a method that allows you to fine-tune large pretrained models for specific tasks without retraining the entire model. Instead of modifying all parameters, PEFT introduces learnable parameters to optimize “soft” prompts, enhancing the model’s performance. This approach significantly reduces computational costs and storage requirements, making it ideal for resource-constrained environments.
Developed by Hugging Face, PEFT integrates seamlessly with their ecosystem, including Transformers and Accelerate. This integration ensures you can easily adapt it to your workflows without complex setups. Whether you’re a researcher or developer, PEFT provides a streamlined way to fine-tune models efficiently.
Aspect | Description |
|---|---|
Definition | |
Core Concept | It introduces learnable parameters to optimize ‘soft’ prompts, enhancing model performance. |
Integration | PEFT is part of Huggingface’s library, seamlessly integrating with Transformers and Accelerate. |
Key Features of PEFT
PEFT offers several features that make it a standout tool for fine-tuning large language models:
Parameter Efficiency: Only 1.4% of the total model parameters are trainable during fine-tuning, demonstrating its high efficiency.
Seamless Integration: Works effortlessly with Hugging Face’s tools, ensuring compatibility with popular frameworks.
Resource Optimization: Reduces memory usage and computational demands, enabling fine-tuning on consumer-grade hardware.
Performance Gains: Achieves results comparable to fully fine-tuned models while using fewer resources.
When using PEFT, you can expect significant improvements in fine-tuning tasks. For instance, metrics like rouge1 increased by 18%, rouge2 by 10%, and rougeL by 13%. These results highlight its ability to enhance performance while minimizing resource consumption.
Purpose and Applications of PEFT
PEFT is designed to address the challenges of fine-tuning large models in resource-limited settings. It is particularly useful when you need to adapt models for specific tasks without the overhead of retraining. Common applications include:
Text Summarization: Fine-tune models to generate concise and accurate summaries.
Sentiment Analysis: Adapt models to classify sentiments in text data.
Conversational AI: Train models for chatbots and virtual assistants with minimal adjustments.
The library’s efficiency makes it suitable for researchers and developers working with limited hardware. By reducing the number of trainable parameters, PEFT ensures you can achieve high performance without compromising on resource efficiency. This makes it a valuable tool for PEFT Unsloth Parameter-Efficient Fine-Tuning, especially when balancing performance and cost.
PEFT Unsloth Parameter-Efficient Fine-Tuning: Head-to-Head Comparison

Performance
When comparing performance, Unsloth excels in speed and memory efficiency. It achieves up to 2x faster processing while using 70% less memory. This makes it ideal for tasks requiring rapid execution. For instance, LoRA, when optimized with Unsloth, demonstrates higher throughput, showcasing its superior resource utilization. On the other hand, PEFT focuses on parameter efficiency. It fine-tunes models by training only a small fraction of parameters, which slightly impacts performance in some cases but remains comparable to full fine-tuning.
Method | Resource Utilization | Performance Impact |
|---|---|---|
PEFT | Slight degradation in some scenarios | |
Unsloth | Higher resource usage | Comparable to full fine-tuning |
Unsloth’s dynamic quantization further enhances its performance by balancing accuracy and memory usage. PEFT, however, shines in resource-constrained environments, enabling fine-tuning on consumer-grade hardware.
Ease of Use
Both tools prioritize user accessibility, but their approaches differ. Unsloth offers beginner-friendly notebooks, allowing you to add datasets and run models with minimal effort. Its simple installation process via pip and compatibility with Linux and Windows make it highly approachable. PEFT, integrated into Hugging Face’s ecosystem, provides seamless workflows for users already familiar with Transformers and Accelerate. This integration simplifies the process for experienced developers.
Unsloth’s focus on user-friendliness benefits those new to fine-tuning, while PEFT’s ecosystem integration appeals to advanced users seeking streamlined operations.
Scalability
Scalability is a critical factor when working with large models. Unsloth supports long-context reasoning and advanced reinforcement learning, making it suitable for complex tasks. Its optimization for NVIDIA GPUs ensures smooth performance even with large datasets. PEFT, however, stands out in resource efficiency. It significantly reduces memory, disk, GPU, and CPU usage during model tuning, making it highly scalable for large-scale applications.
For projects requiring extensive scalability, PEFT’s ability to adapt to resource constraints proves invaluable. Unsloth, with its focus on performance and memory optimization, also scales effectively for demanding tasks.
Cost
When considering cost, both Unsloth and PEFT offer unique advantages depending on your priorities. Unsloth focuses on reducing memory usage and improving processing speed, which can lower hardware costs. By using 70% less memory, Unsloth allows you to work with advanced models like Llama 3.3 and Mistral without requiring high-end GPUs. This efficiency can save you money, especially if you frequently fine-tune large models.
PEFT, on the other hand, excels in minimizing computational resources. It fine-tunes models by training only a small fraction of parameters, which significantly reduces the need for expensive hardware. For example, PEFT requires only a few thousand samples for fine-tuning, making it a cost-effective choice for large-scale applications. This approach not only saves time but also cuts down on electricity and storage expenses. Although PEFT incurs a slight performance loss of about 1 to 1.7% across ROUGE metrics, the resource savings often outweigh this trade-off.
If you prioritize speed and memory efficiency, Unsloth may align better with your needs. However, if you aim to fine-tune models on a tight budget or with limited hardware, PEFT offers a more economical solution. Both tools provide cost-effective ways to optimize large language models, but your choice will depend on the specific requirements of your project.
Pros and Cons
Advantages of Unsloth
Unsloth offers several benefits that make it a standout tool for fine-tuning large language models. Here are some of its key advantages:
Exceptional Speed and Memory Efficiency: Unsloth achieves up to 2x faster performance while reducing memory usage by 70%. This makes it ideal for tasks requiring rapid execution and efficient resource utilization. For example, when fine-tuning models like Mistral 7b, Unsloth delivers a 1.88x speed multiplier with a 65.9% reduction in VRAM usage.
Wide Model Compatibility: You can use Unsloth with a variety of advanced models, including Llama 3.2, Qwen 2.5, and Phi-4. This ensures you have access to the latest AI advancements.
Optimized for Long-Context Reasoning: Unsloth excels in tasks requiring deep contextual understanding, such as conversational AI and reasoning tasks.
User-Friendly Design: The platform provides beginner-friendly notebooks and a simple installation process. This makes it accessible even if you’re new to fine-tuning.
The following table highlights Unsloth’s performance metrics compared to other methods:
Model | Dataset | 🤗 Performance | 🤗 + Flash Attention 2 | VRAM Savings | |
|---|---|---|---|---|---|
Code Llama 34b | Slim Orca | 1x | 1.01x | 1.94x | -22.7% |
Llama-2 7b | Slim Orca | 1x | 0.96x | 1.87x | -39.3% |
Mistral 7b | Slim Orca | 1x | 1.17x | 1.88x | -65.9% |
Tiny Llama 1.1b | Alpaca | 1x | 1.55x | 2.74x | -57.8% |
Disadvantages of Unsloth
While Unsloth excels in many areas, it has some limitations. These include:
Hardware Dependency: Unsloth performs best with NVIDIA GPUs. If you lack access to compatible hardware, you may face challenges in achieving optimal results.
Limited Ecosystem Integration: Unlike PEFT, Unsloth does not integrate directly with popular frameworks like Hugging Face Transformers. This may require additional effort to adapt it to your workflows.
Advantages of PEFT
PEFT provides unique benefits that make it a valuable tool for fine-tuning large models. Here are its main advantages:
Parameter Efficiency: PEFT fine-tunes models by training only a small fraction of parameters. For instance, it trains just 0.19% of parameters in some cases, significantly reducing computational demands.
Resource Optimization: You can fine-tune models on consumer-grade hardware, making PEFT accessible even if you have limited resources.
Seamless Integration: PEFT integrates effortlessly with Hugging Face’s ecosystem, including Transformers and Accelerate. This simplifies workflows and enhances usability.
Performance Gains: Despite its parameter efficiency, PEFT achieves results comparable to fully fine-tuned models. For example, it improves metrics like rouge1 by 18%, rouge2 by 10%, and rougeL by 13%.
The following chart illustrates PEFT’s performance improvements across various metrics:
By focusing on parameter efficiency and resource optimization, PEFT ensures you can achieve high performance without overburdening your hardware.
Disadvantages of PEFT
While PEFT offers remarkable efficiency, it does come with certain limitations that you should consider before choosing it for your project.
Performance Variability Across Model Sizes: PEFT’s performance depends heavily on the size of the model you are fine-tuning. For smaller models, PEFT often delivers worse results compared to full parameter fine-tuning. Medium-sized models show improvement, but full fine-tuning still outperforms PEFT. Only with large models does PEFT achieve comparable performance. This variability can limit its applicability if you work with smaller or medium-sized models.
Model Size | PEFT Performance | Full Parameter Fine-tuning Performance |
|---|---|---|
Small | Worse | Better |
Medium | Improving | Better |
Large | Comparable | Better |
Slight Performance Trade-offs: PEFT’s parameter-efficient approach sometimes leads to minor performance degradation. For example, metrics like ROUGE may drop by 1% to 1.7% compared to full fine-tuning. While this trade-off is small, it can impact tasks requiring the highest accuracy, such as critical decision-making systems.
Dependency on Hugging Face Ecosystem: PEFT integrates seamlessly with Hugging Face tools like Transformers and Accelerate. However, this reliance can pose challenges if your workflow involves other frameworks. You may need additional effort to adapt PEFT to non-Hugging Face environments.
Note: If your project involves smaller models or demands peak performance, PEFT might not be the best fit. Evaluate your requirements carefully to ensure it aligns with your goals.
By understanding these limitations, you can make an informed decision about whether PEFT suits your specific needs.
Use Cases

When to Use Unsloth
Unsloth works best when you need speed and memory efficiency for fine-tuning large language models. If your project involves tasks like conversational AI or reasoning that require long-context understanding, Unsloth provides a reliable solution. Its ability to reduce memory usage by 70% while doubling processing speed makes it ideal for scenarios where hardware resources are limited. For example, when fine-tuning models like Mistral 7b, Unsloth achieves a 1.88x speed multiplier and reduces VRAM usage by 65.9%.
Unsloth also shines in projects requiring high throughput. By optimizing LoRA with Unsloth, you can achieve faster performance without compromising accuracy. The following table highlights how Unsloth enhances memory usage and throughput:
Evidence Type | Description |
|---|---|
Memory Usage | QLoRA consistently shows the lowest memory usage due to pre-trained weights represented at lower precision. |
Throughput | LoRA, utilizing Unsloth for optimization, demonstrates higher throughput performance. |
If you are new to fine-tuning, Unsloth’s beginner-friendly notebooks and simple installation process make it an excellent choice. You can quickly set up your environment and start working on your datasets without technical hurdles. Whether you are a researcher or developer, Unsloth helps you achieve efficient fine-tuning with minimal effort.
When to Use PEFT
PEFT is the right choice when you need to fine-tune large models in resource-constrained environments. If your hardware lacks the capacity for full fine-tuning, PEFT allows you to adapt models by training only a small fraction of parameters. This approach significantly reduces computational demands, enabling you to work on consumer-grade hardware.
PEFT excels in applications like text summarization, sentiment analysis, and conversational AI. For instance, it improves metrics like rouge1 by 18%, rouge2 by 10%, and rougeL by 13%, delivering results comparable to fully fine-tuned models. Its seamless integration with Hugging Face’s ecosystem ensures you can easily incorporate it into your workflows if you already use tools like Transformers or Accelerate.
If cost is a concern, PEFT offers a budget-friendly solution. By reducing memory and storage requirements, it minimizes expenses related to hardware and electricity. This makes it a practical option for large-scale projects or when working with limited resources. Whether you are a seasoned developer or an AI enthusiast, PEFT provides an efficient way to fine-tune models without overburdening your system.
Both Unsloth and PEFT offer unique advantages for fine-tuning large language models. If you need faster processing and reduced memory usage, Unsloth provides an excellent solution. It works well for tasks like long-context reasoning or when hardware resources are limited. PEFT, however, shines in resource-constrained environments. Its parameter-efficient design minimizes computational demands, making it a cost-effective choice. You should evaluate your project’s goals and resources to decide which tool aligns better with your needs. Each tool excels in its own way, ensuring you can achieve efficient and effective fine-tuning.
FAQ
What is the main difference between Unsloth and PEFT?
Unsloth focuses on speed and memory efficiency, making it ideal for tasks requiring rapid execution. PEFT emphasizes parameter efficiency, allowing you to fine-tune models with minimal resource usage. Your choice depends on whether you prioritize performance or resource constraints.
Can I use Unsloth and PEFT on the same project?
Yes, you can combine both tools. Use Unsloth for tasks needing high-speed processing and memory optimization. Apply PEFT for parameter-efficient fine-tuning when working with limited hardware. This hybrid approach maximizes efficiency and performance.
Which tool is better for beginners?
Unsloth offers beginner-friendly notebooks and a simple setup process, making it easier for new users. PEFT integrates with Hugging Face’s ecosystem, which suits those familiar with its tools. Choose based on your experience level and workflow preferences.
Do Unsloth and PEFT support the same models?
Unsloth supports models like Llama 3.3, Mistral, and DeepSeek-R1. PEFT works with Hugging Face-compatible models, including bigscience/mt0-large. Check your project’s model compatibility before deciding which tool to use.
How do these tools save costs?
Unsloth reduces memory usage by 70%, lowering hardware requirements. PEFT minimizes computational demands by fine-tuning only a small fraction of parameters. Both tools help you save on hardware and energy costs, depending on your project’s needs.